Introduction - GPU Programming
One of the main advantages of using C++ is that you have very finely tuned performance - you can control basically everything about your program, and don't use unnecessary resources of have the overhead that languages like Java and C# have. As such, C++ programmers should be very familiar with how CPUs and RAM work.
However, accessing the GPU is very beneficial: GPUs are specialized for performing mathemetical calculations, and so being able to do work (or offload work) onto a GPU, in addition to a CPU, makes for strong programming. In this blog post, we'll look at GPU programming by using CUDA. Prerequisite: You Need A GPU On Your Computer
Obviously, to program with a GPU, you need to actually have a GPU. Some laptops use CPUs with integrated graphics cards, which probably aren't CUDA enabled. For a list of CUDA-enabled GPUs, click here.
And if you're using Windows, you need Visual Studio installed. I recommend having Visual Studio 2017. (You should honestly have it anyway.) Here's a link to download it. Installation
To be able to compile C++ code that runs on the GPU, you'll need the CUDA toolkit. Click here to download it. Choose your operating system, architecture, and version. For installer type, choose local. (Either is fine, but I like local.) Click the download button, and follow the instructions that are written.
After the download finishes, launch the installer. Follow the on-screen instructions. (I recommend doing a Custom install, and making sure everything is checked.)
If you're on Windows, you need to make sure the PATH environment variable points to your visual studio bin, otherwise you'll get a "can't find cl.exe" problem when trying to compile. See the video to see how to set this. Hello World Code
So we need some actual C++ code to actually utilize our GPU. (Note, this code is taken (but modified) from this tutorial.) Put the following code in a file named main.cu
The code is simple: we have a function that adds to arrays together (into the second array). We have some code in main that allocates memory for two arrays, calls the add functions, checks if the computation worked, and then frees the memory. Basic programming.
Compiling and Running The Code
So we have our code file, now we need to compile it. Open a terminal in your current directory (for Windows, see the video if you don't know how that works), and to compile the code, in the terminal run:
nvcc main.cu -o run
This will generate our executable file. To run it, next in the terminal, run:
./run
The output will show "Max error: 0".
Next Steps
So we installed some CUDA tools and successfully ran some GPU enabled code on our computer. Now we need to do some more advanced programming to learn how to optimize our code and do even more. I recommend reading through this article and following the links there. It's possible that in the future I'll do more on this topic, so make sure to follow me using the links below.
Like this content and want more? Feel free to look around and find another blog post that interests you. You can also contact me through one of the various social media channels.
Twitter: @srcmake Discord: srcmake#3644 Youtube: srcmake Twitch: www.twitch.tv/srcmake Github: srcmake
To watch the youtube video explaining this topic, click here.
Prerequisite: You Should Know About Pointers And References
Make sure you check out the blogpost on pointers and references, because this topic will be a continuation of that.
In this blog post, we'll be going over what R-Values (and L-Values) are, what R-Value References are, and what Move Semantics are. We'll also look at std::move. If you're a good, modern C++ programmer, then you should know this. Note: It's possible to get more technical (and accurate) about the concepts I'll mention, but we'll keep it simple to start out with. What Are L-Values and R-Values
L-Values and R-Values are category types that describe variables, function returns, and objects in C++.
An L-value is stored in memory and will exist on the next line of code. An R-Value is temporary and won't exist (in memory) on the next line of code. Let's go through some code examples.
A simple rule of thumb (that isn't entirely accurate) is "if it can be on the left side of an equal sign, it's an L-Value. Otherwise, it's an R-Value."
R-Value References
Okay, so remember references from the last blog post? The & sign that means a variable refers to something that already exists in memory (instead of making a copy)? Well, the & sign only works with L-Value references. If you use the && sign, then you mean you want an R-Value reference, specifically.
Let's look at some code to see how this works.
Make sure you compile with C++ version 11 or higher.
The copy way works like this:
The R-Value reference way works like this:
NOTE: Line 13 won't actually do a real "copy" because of Return Value Optimization (which basically means the compiler will just put the value into a directly, because the compiler is smart, and the thing that function srcString() returns is very clear to the compiler (with no chance of something else being returned). That line is mostly meant as a simple example.
This type of reference is powerful: we no longer have to spend time and space with copies, we can just keep the same variables (or objects) in memory that would have been removed.
std::move
std::move is a standard library function that takes an L-Value or R-Value, and casts it to an R-Value.
In the following code, move will convert the L-Value to an R-Value, which means that the R-Value will go into the overloaded function meant for R-Values.
So why use std::move? Use it when you want to convert an L-Value to an R-Value (presumably to call an overloaded function). The primary use case is when you don't care about what happens to the value of the variable/object after you use it, as seen in move semantics.
Move Semantics
Move Semantics is a simple concept, but you need to understand and use the stuff from the previous sections to really make use of it: Copying is expensive. If we don't care about what happens to the value of a variable/object after using it, then use R-Value References.
The way you actually use move semantics is through a special move constructor/assignment operator, that will be called instead of a copy constructor/assignment operator. The difference will be that the move constructor/assignment operator will have a && sign.
(This is also what makes the Rule of 3 into the Rule of 5.)
It's also possible to have special move functions in a class implemented depending on certain situations.
One very easy example to see who move semantics is good is with a swap function. With a normal "copy" version of swap, there's an extra copy being used.
What's really going on is something like this:
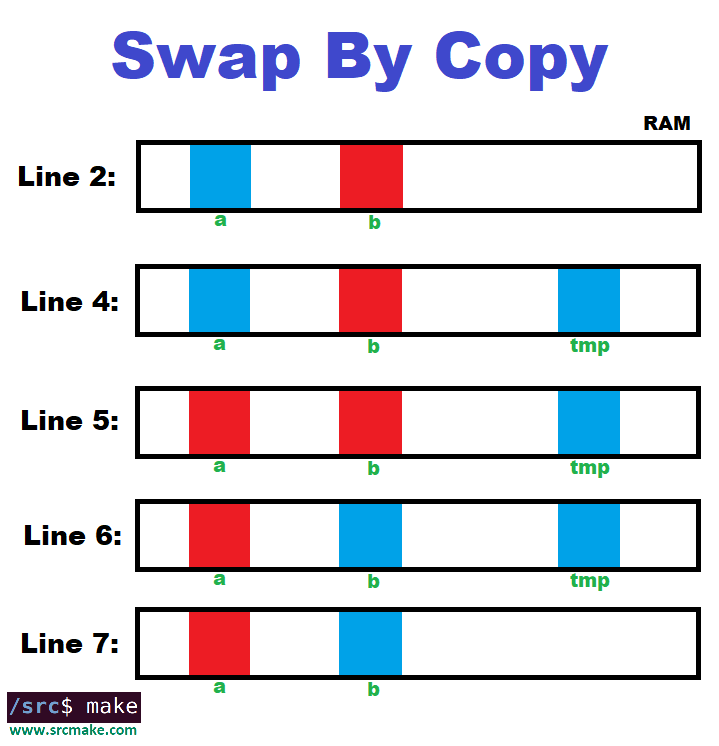
You see that an extra T (which could be a variable, an object, a container, etc.) named tmp must be generated in RAM for the swap to occur. If we're dealing with a large container like a vector, this is bad. Move semantics is better.
The following code will be more efficient (assuming that class T has a move constructor defined).
The following code is explained in the following picture:
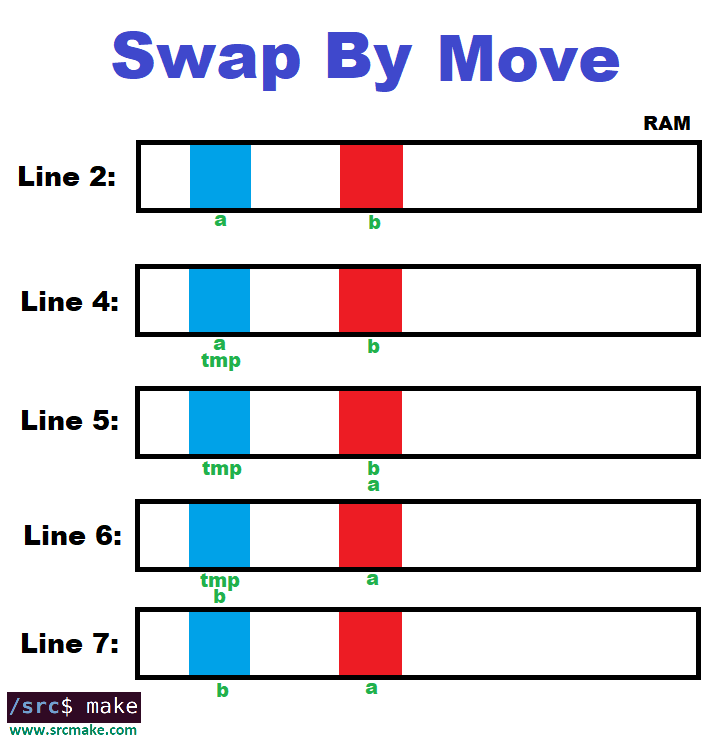
The above code generally changes depending on what T's move constructor will do, but in a simple case, we can see that tmp temporarily points to the exact place in memory for item a, let's a point to b's item, and then let's b point to a's item.
This is much more efficient, as we don't need to allocate memory for an extra temporary variable/container/object. Conclusion
In this blog post, we covered the topic of R-Values, R-Value Reference, std::move, and the concept of Move Semantics in C++. However, it's a bit hard to really grasp the concept without actually writing code and thinking about how to define a move constructor and a move assignment operator.
In a future blog post, we're going to implement the Rule of 5 by making our own Vector class, and it'll teach us how to actually make and code with Move Semantics in mind.
Like this content and want more? Feel free to look around and find another blog post that interests you. You can also contact me through one of the various social media channels.
Twitter: @srcmake Discord: srcmake#3644 Youtube: srcmake Twitch: www.twitch.tv/srcmake Github: srcmake |
AuthorHi, I'm srcmake. I play video games and develop software. Pro-tip: Click the "DIRECTORY" button in the menu to find a list of blog posts.

License: All code and instructions are provided under the MIT License.
|
