[Interview Question] Find The Lowest Common Ancestor In Binary (Search) Tree (Both BT and BST)3/1/2020
To watch the youtube video on this topic where I explain everything, please click here.
Introduction
This series of problems asks to find the "lowest common ancestor" for two types of binary trees.
A "common ancestor" for two nodes is a node that has those two nodes as descendants (and a node can be a descendants of itself). The "lowest" common ancestor is the node that's closest to the two nodes that satisfies the common ancestor condition. [Easy] Find Lowest Common Ancestor In Binary Search Tree
Given the root of a binary search tree and two nodes in the tree, p and q, find the lowest common ancestor of p and q. (Problem on Leetcode.)
For example, in the following diagram if p is node 3 and q is node 1, then the LCA(p,q) is node 2. 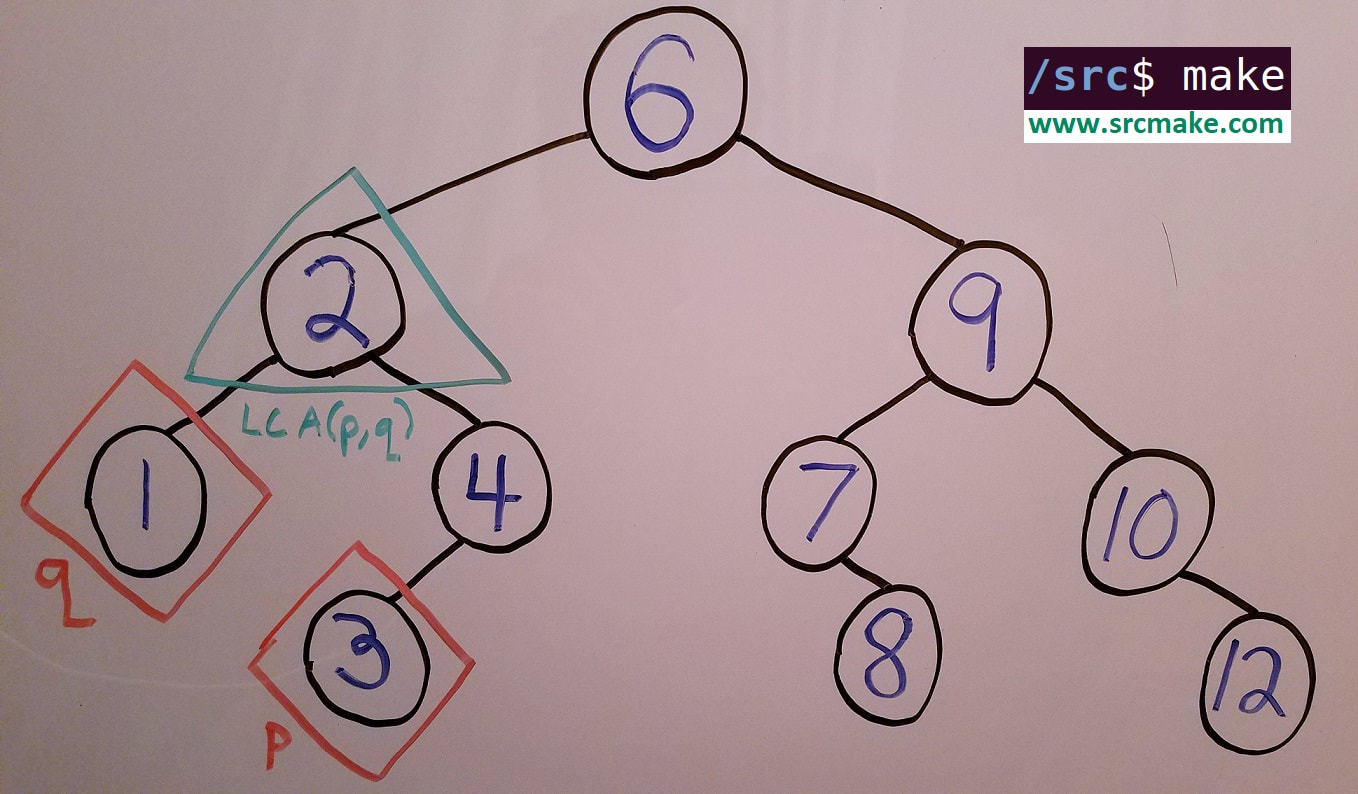
A binary search tree that shows the lowest common ancestor of two nodes, p and q.
Solution (Iterative)
We'll recognize that the node that's the LCA node of p and q must be one of the following:
For this solution, we'll take advantage of the "search" property of Binary Search Trees. In a BST, a node's left children have values that are less than the node's value, and the node's right children have values that are greater than the node's value. Because of this, we'll know if the p is on the left and q is on the right without having to search those subtrees. The C++ solution to the problem is as follows:
The time complexity is O(N). (Specifically O(H) where H is the height of the tree.)
The space complexity is O(1) because we're not using any extra space.
Note: We choose the iterative solution here because the recursive solution has a space complexity of O(N). However, he code itself is basically the same as the iterative approach.
[Medium] Find Lowest Common Ancestor In Binary Tree
Given the root of a binary tree and two nodes in the tree, p and q, find the lowest common ancestor of p and q. (Problem on Leetcode.)
For example, in the following diagram if p is node 2 and q is node 9, then the LCA(p,q) is node 7. 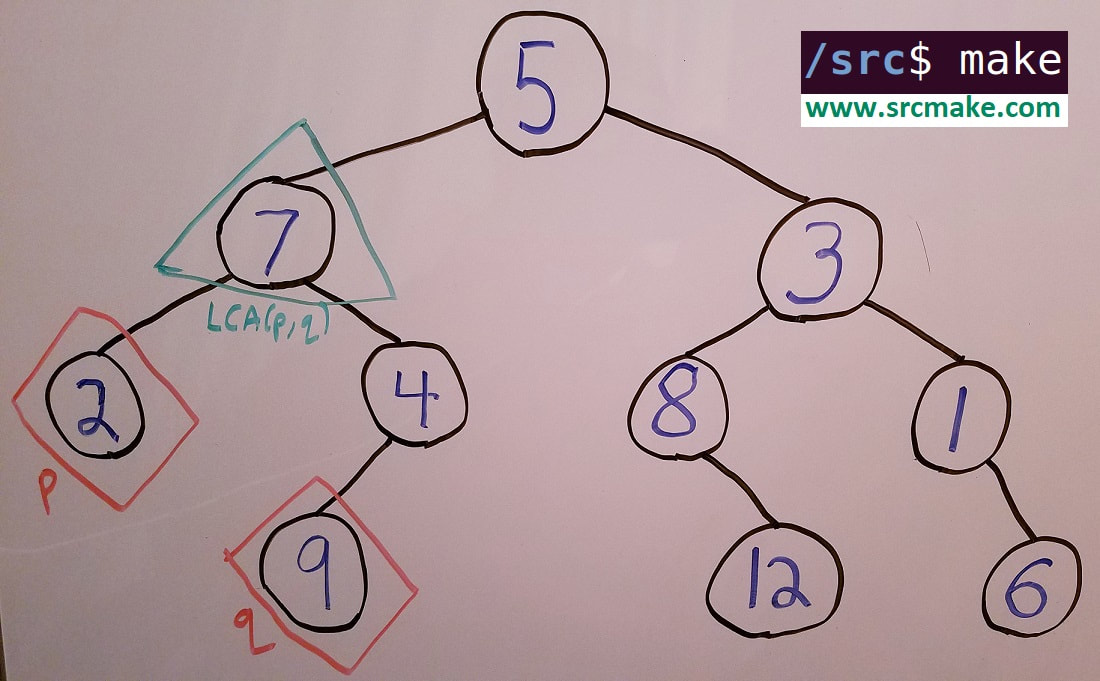
A binary tree that shows the lowest common ancestor of two nodes, p and q.
Solution (Recursive)
Like the previous solution, we'll recognize that the node that's the LCA node of p and q must be one of the following:
However, this time we have a regular binary tree, and so we're forced to look through the entire tree until we find p and q. Our strategy is, for each node, recursively check the left and right subtrees to determine if either subtree has p or q in it. The node that satisfies one of these conditions is the lowest common ancestor.
The time complexity is O(N), because our recursion visits each node exactly once.
The space complexity is O(N) because we potentially hold the entire tree in memory at the same time.
Note: We choose the recursive solution here because the code/algorithm is simpler. The iterative solution's code is harder and requires a stack.
Like this content and want more? Feel free to look around and find another blog post that interests you. You can also contact me through one of the various social media channels.
Twitter: @srcmake Discord: srcmake#3644 Youtube: srcmake Twitch: www.twitch.tv/srcmake Github: srcmake
To watch the youtube video going over this topic, please click here.
Problem Statement
Given an array, for each element find the next greater element (to the element's right). If there is no greater element then the value is -1.

The next greater element.
Approach 1: O(N^2) Time | O(1) Space - For Each Element, Look Right
The naive approach is pretty simple and uses nested loops. For each element of the array, look to the elements to its right. If we find a greater element, cool. If not (and we've looked at every element to the right), then the next greater element is -1.
Here's some pseudocode that demonstrates this algorithm.
The time complexity is O(N^2) since every element potentially has to visit every element to its right.
The space complexity is O(1) since we don't use any extra space. Approach 2 (Best): O(N) Time | O(N) Space - Use A Stack
One way to solve the problem is with a stack.
The stack stores the index of elements that don't have their NGEs yet. Every time we visit an element, we check if is value is greater than the element on top of the stack. The following picture shows the setup we need to use a stack to find the NGE of each element in the array. We'll go through that particular example in the video. (So watch the video if you want to see how it works.) 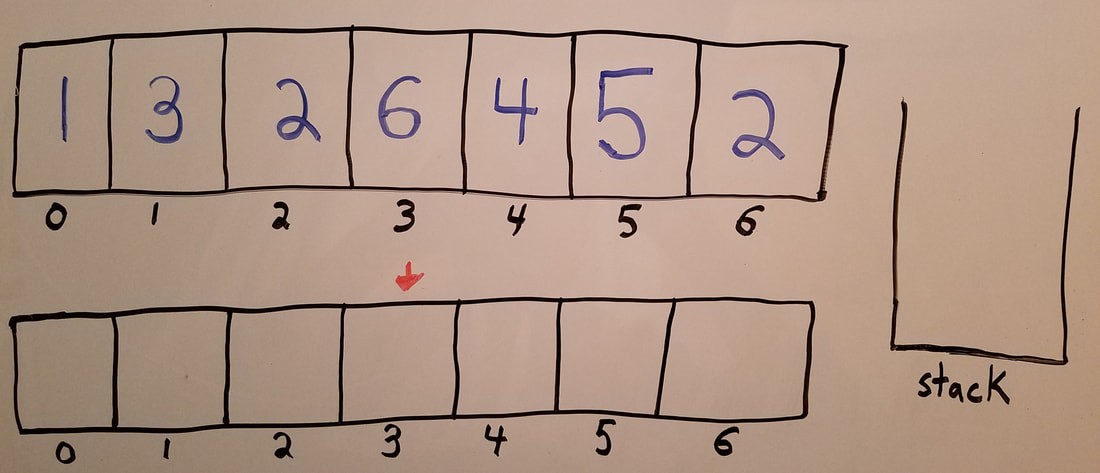
An array, and an empty stack. (Along with the empty array which needs to be filled with the next greater element.)
The following pseudocode demonstrates the algorithm.
The time complexity is O(N) since we visit each element only once.
The space complexity is O(N) since at worst we have to put all elements onto the stack.
The source code of a working implementation (written in C++) can be found on github here.
Optimizations
There are possibly optimizations, regardless of the algorithm chosen:
Edge Cases
Edge cases to cover:
Like this content and want more? Feel free to look around and find another blog post that interests you. You can also contact me through one of the various social media channels.
Twitter: @srcmake Discord: srcmake#3644 Youtube: srcmake Twitch: www.twitch.tv/srcmake Github: srcmake
Resources
1. https://www.geeksforgeeks.org/next-greater-element/ To watch the video that goes over this topic (which also visualizes the example section), click here. What Are Bloom Filters?A Bloom Filter is a data structure that uses multiple hash functions on a key to mark values in a boolean array. The point of a bloom filter is to store whether a key was visited before. An example use-case for a Bloom Filter might be a web crawler, which needs to store whether we've visited a website before.  A basic bloom filter consists of some hashes and an array of booleans. Bloom Filters are NOT about key-value pairs like Hash Maps. There's no "value" associated with a key. The only thing we care about for a key is a boolean: true that we've seen this key before, or false that this key is new. Bloom filters are good because they use less memory than a hash map and still provide fast lookup and insertion times. The reason bloom filters aren't incredibly common is because it's possible they give wrong answers: a Bloom Filter might say that you've visited a key before when you really haven't. We'll see this in the upcoming example section. How Bloom Filters WorkA bloom filter can be represented as a list of k hash functions and an array of booleans that starts off with all values initialized to false. A hash function is simply a function that takes some input, and transforms that into some number (which we'll use as the index in our array) as output. The same input will always produce the same output. We care about two operations in a bloom filter:
Insertion works by inputting a key into all k hash functions, and for each outputted array index, marking that array value as true. Querying works by inputting a key into all k hash functions, and for each outputted array index, checking whether that array value is true. If all array values are true, then the key was seen before. If any array values are false, then the key wasn't seen before. The time complexity of inserting and querying are both O(k). Bloom Filter ExampleLet's say we have a bloom filter with an array initialized to false (and pretend our array can hold negative numbers), and let's say k=3 so that we have 3 hash functions (which takes a string s as input, for simplicity).  A bloom filter initialized. The following operations show the various interactions with a bloom filter (I'll show these in the video):
ConclusionBloom Filters are important data structures and they're frequently asked about in interviews. They're good because they're efficient on space, but the drawback is that they produce false positives, possibly saying it's seen a key before when it really hasn't. We've only looked at a basic bloom filter example to get the concept behind them, because optimizing a real bloom filter takes a lot of tuning to decide a good k and depends on the amount of memory you have. And of course, we saw no code today because the basic concept of a bloom filter is easy enough to code, but coding a real one is a bit involved (because of the complex nature of making good hash functions). Keep this data structure in mind during interviews and bookmark this page if you ever need a refresher. Like this content and want more? Feel free to look around and find another blog post that interests you. You can also contact me through one of the various social media channels.
Twitter: @srcmake Discord: srcmake#3644 Youtube: srcmake Twitch: www.twitch.tv/srcmake Github: srcmake |
AuthorHi, I'm srcmake. I play video games and develop software. Pro-tip: Click the "DIRECTORY" button in the menu to find a list of blog posts.

License: All code and instructions are provided under the MIT License.
|
